
Esta entrada pretende ser una introducción muy informal a conceptos musicales que se necesitan para comenzar en el mundillo de la música de 8 bits, o música chiptune. Las ideas son generales aunque se utilizará un programa de composición concreto (Arkos Tracker 2) orientado a un chip concreto (AY-3-8910). Creo que no es difícil extrapolar a otros programas (llamados trackers) o a otros chips.
Insisto en el punto de que la introducción será informal. Mi objetivo es contar lo mínimo para que podamos empezar lo antes posible a componer con trackers. Muchas cosas se irán desarrollando en próximas entradas.
Música para sistemas de 8 bits
Con esto nos referimos a componer música que va a ser interpretada por sistemas digitales de 8 bits que poseen chips de audio de los años 80. Es decir, crear canciones para programas o videojuegos de máquinas como la Nintendo Gameboy, NES y ordenadores MSX, Spectrum, Commodore, etc., o incluso a máquinas recreativas. Puede crearse cierto dilema si consideramos que internamente los chips de audio no tienen por qué ser sistemas digitales de 8 bits. Suelen tener un interfaz de 8 bits mediante el cual se le envián comandos para que se generen los sonidos, pero internamente pueden funcionar con más bits, o incluso con componentes analógicos. De todas formas, al decir que son chips de los años 80 y que se asociaban principalmente a videojuegos de los sistemas de la época, creo que se simplifica todo esto.
De forma breve comento que estos chips de audio son capaces de generar sonidos y de ahí su capacidad de generar música o efectos de sonido. Normalmente existe una limitación en el número de sonidos simultáneos que se puede generar. A cada sonido independiente le llamaré una voz o canal. Por ejemplo, se pueden usar varias voces para crear una melodía (supuestamente agradable al oído) y dedicar alguna otra voz a hacer efectos de disparo, o explosiones o choque. Las voces en los chips más primitivos se basaban en ondas cuadradas (cambios bruscos en la amplitud de la onda acústica oscilando entre dos únicos valores: amplitud baja y amplitud alta) y en ruido (cambios aleatorios en la amplitud utilizando gran cantidad de valores). En un rato doy más detalles, tranquilos. Las ondas cuadradas se utilizaban para melodías y efectos y el ruido para la percusión y para efectos sonoros (explosiones, golpes, las olas del mar…). Cuándo se producían estos sonidos y cuáles eran sus propiedades quedaba determinado por comandos que se introducían digitalmente en el chip. Realmente, lo que ocurría es que una CPU (o cualquier otro sistema digital) accedía a un puerto de entrada del chip de audio escribiendo datos en registros. Cada registro permitía modificar distintos parámetros. Por ejemplo, podíamos modificar la frecuencia y amplitud de una de las voces y posteriormente apagar su volumen. Con esto se conseguía que sonase una nota musical durante un tiempo controlado.
A continuación os pongo un ejemplo utilizando el chip AY-3-8910 (3 ondas cuadradas) en el que:
1. Suena la voz 1 (acompañamiento 1)
2. Suena la voz 2 (melodía)
3. Suena la voz 3 (acompañamiento 2) – Aquí se usan arpegios que se ejecutan muy rápido y da la
impresión de que hay más de una nota simultánea.
4. Suenan las voces 1 y 2
5 Suenas las voces 1, 2 y 3 (se repite varias veces con una melodía más amplia)
Resumiendo:
- Disponemos de un chip de audio
- El chip permite generar varias voces asociadas a sonidos y ruidos
- La generación de sonidos se produce mediante el acceso a los registros de configuración del chip
De acuerdo, falta mucho por explicar, pero ya dedicaré una entrada a profundizar en estos temas.
Notas musicales y escala
Insisto y me pongo pesado, no me importa, yo soy así: no pretendo dar un curso de lenguaje musical sino únicamente presentar lo mínimamente necesario para poder utilizar trackers. Dicho esto continúo.
Empezamos hablando de qué es el sonido. Pero solo veremos el sonido que es interpretado por el ser humano como tal. Podríamos decir que hablaremos del sonido audible y que consiste en cualquier vibración mecánica que es captada por nuestros oídos e interpretada por nuestro cerebro. El sonido necesita un medio físico para que se produzca la propagación de las vibraciones desde el origen de éstas hasta nuestros oidos. De ahí que no haya sonido en el espacio, puesto que el vacío no permite la propagación de ondas mecánicas. Os pongo un ejemplo:
Una persona (José Turing) al hablar hace vibrar sus cuerdas vocales, las cuales ponen en movimiento a las moléculas de aire de alrededor de éstas, creándose una onda. Dicha onda se propaga por el espacio debido a que las moléculas de aire chocan entre sí. Finalmente, la onda llega al oído de otra persona (María Lovelace) y transmitiéndo la vibración del aire a su tímpano. Esta vibración finalmente acaba siendo transformada en impulsos eléctricos que procesa el cerebro y que crean la percepción del sonido. El rango de frecuencias audibles por el ser humando va aproximadamente desde 20 Hz hasta 20 KHz (desde 20 variaciones por segundo hasta 20.000 variaciones por segundo).
Podríamos extender el ejemplo a qué ocurre cuando escuchamos música en con el PC (o cualquier reproductor digital). En el PC dispone del audio en un fichero, que no es otra cosa sino una colección ordenada de números. Esta secuencia de números se procesa obteniendose otra secuencia digital que se corresponden con las variaciones en el tiempo de la amplitud del sonido y que es análoga a la onda acústica. Estas variaciones se transforman en variaciones de la amplitud de una tensión eléctrica que excita mediante inducción la membrana de un altavoz (auricular) la cual vibra haciendo vibrar las moléculas de aire , comenzando así un proceso similar al descrito en el párrafo anterior. Podríamos también buscar la similitud entre el funcionamiento del oído y el de un micrófono, pero mejor paro ya con los ejemplos :).
Destacamos dos parámetros esenciales en el sonido: la frecuencia y la amplitud. La frecuencia es la velocidad de vibración y determina el tono del sonido. Variaciones lentas producen sonidos graves (teclas a la izquierda en un piano) y variaciones rápidas sonidos agudos (teclas a las derecha en un piano). La amplitud determina la intensidad o volumen del sonido.
A partir de este punto es interesante disponer de un teclado para hacer pruebas de sonido. Podéis utilizar el teclado que viene con la aplicación Arkos Tracker 2 (AT2) o cualquier teclado en línea.
PRUEBA:
- Abrir la aplicación AT2
- Hacer click con el ratón en las teclas más a la izquierda y escuchar su sonido [grave]
- Hacer click con el ratón en las teclas más a la derecha y escuchar su sonido [agudo]
Pues vamos con las escalas. Definamos nota músical como la unidad básica con la que se componen las canciones. Una nota musical tiene un sonido diferenciado correspondiente a un conjunto de frecuencias. Las frecuencias están determinadas, no nos vale cualquiera al azar. Por ejemplo, el la de concierto tiene una frecuencia de 440 Hz (440 cambios por segundos). Si duplicamos la frecuencia obtenemos la misma nota pero una octava más alta (la nota la se encuentra a 440 Hz y a 880 Hz). Si dividimos la frecuencia entre 2 obtendríamos la misma nota pero una octava más baja (la nota la se encuentra a 440 Hz, pero también a 220 Hz). Al escuchar sonidos a frecuencias 220 Hz, 440 Hz, 880 Hz, etc., nuestro cerebro es capaz de identificar todas las nota como la, pero cada una estará en una octava diferente sonando más graves o más agudas según sus frecuencias sean bajas o altas, respectivamente.
En la siguiente muestra de audio se escuchan 6 notas.
- LA octava 2 de AT2 (A-2)
- LA octava 3 de AT2 (A-3)
- LA octava 4 de AT2 (A-4)
- DO octava 2 de AT2 (C-2)
- DO octava 3 de AT2 (C-3)
- DO octava 4 de AT2 (C-4)
En la figura vemos el nombre que se le da a las notas en el teclado del piano: do, re, mi, fa, sol, la, si (en notación anglosajona C, D, E, F, G, A, B). Se han representado 3 octavas completas. Las teclas de la izquierda producen notas con frecuencias bajas y conforme nos desplazamos a la derecha las frecuencias van incrementándose haciendo que las notas se hagan más agudas. Se observa la naturaleza cíclica de las notas; por ejemplo la nota do ser repite tres veces en el dibujo. Sabemos que la frecuencia de la nota do de la primera octava (la más a la izquierda) es la mitad que la frecuencia que la ntoa do que está en la siguiente octva (octava central), y así sucesivamente.
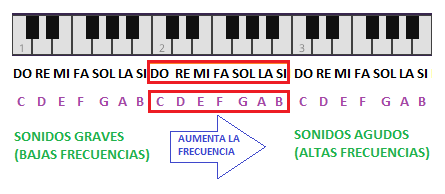
Notas musicales en el teclado del piano
PRUEBA: Intentar tocar las seis notas del audio anterior
En el sistema musical occidental utilizamos la escala cromática, compuesta por 12 notas diferentes que están separadas entre sí un semitono. La escala de doce notas es cíclica: si interpretamos las notas de forma ascendente y llegamos a la última nota – la duodécima- añadir un semitono a ésta para obtener una decimotercera nota nota implica repetir la primera nota de la escala pero en una octava inmediatamente superior. Todo esto podemos verlo en la figura anterior.
Si recorremos en orden la escala cromática se produce una sensación de ascenso (descenso si invertimos el orden), pero no realmente de melodía. Se utiliza bastante para crear ambiente de misterio, terror, tensión, etc. En la figura vemos un par de ejemplos de escalas cromáticas situadas en el teclado de un piano.
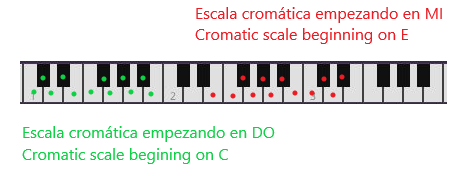
Cromatic scales beginning on C and E/Escalas cromáticas comenzando en DO y MI
Ahora escuchemos varios ejemplos:
- 12 notas de la escala cromática en DO
- “Paseo” por la escala cromática en DO
- 12 notas de la escala cromática en MI
- “Paseo” por la escala cromática en MI
PRUEBA: Practique la escala cromática.
Podemos extraer un subconjunto de notas de los 12 sonidos de la escala cromática para formar numerosas escalas nuevas cada una creando un ambiente característico: alegría, tristeza, misterio, dramatismo, etc. Nos centraremos únicamente en los denominados modos mayores y menores.
Para poder hacer esto nos falta dar nombre a las teclas negras del piano. En general si queremos expresar que una nota debe sonar un semitono más alta se indica con el símbolo # (sostenido – sharp en inglés) . Por ejemplo la nota DO# en el piano se correspondería con la tecla negra inmediatamente superior al DO (en cualquier octava). Para expresar que la nota debe sonar un semitono más baja se utiliza el símbolo ♭ (bemol – flat en inglés). Por ejemplo el SOL♭ sonaría al pulsar la tecla negra inmediatamente inferior a la tecla del SOL. Se observa que FA# y SOL♭ suenan igual. Esta redundancia está relacionada con la forma en la que se crean las escalas y para entender esto bien habría que dedicar más tiempo, pero digamos que tiene que ver con la nota base (la primera nota) de la escala que estemos usando y también con su modo (por ejemplo, mayor o menor). Veamos ahora todos los nombres de las notas (teclas):
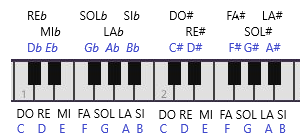
All musical notes/Todas las notas musicales
Escalas mayores y menores
Tal como he comentado, las escalas se forman eligiendo notas entre las 12 notas de la escala cromática. Deben tener una nota de referencia que se denomina nota base (o tónica) que se corresponde con la primera nota de la escala. Como hay muchas escalas, sólo nos referimos aquí a los modos mayor y menor.
Modo mayor
El modo mayor está compuesto por 7 notas y debe cumplir la siguiente relación entre las mismas:
- 1-2: El intervalo musical entre la primera nota y la segunda es de 1 tono (2 semitonos)
- 2-3: El intervalo musical entre la segunda nota y la segunda es de 1 tono (2 semitonos)
- 3-4: El intervalo musical entre la tercera nota y la cuarta es de 1 semitono
- 4-5: El intervalo musical entre la cuarta nota y la quinta es de 1 tono
- 5-6: El intervalo musical entre la quinta nota y la sexta es de 1 tono
- 6-7: El intervalo musical entre la sexta nota y la séptima es de 1 tono
- 7-8: El intervalo musical entre la séptima nota y la octava es de 1 semitono
De forma esquemática -> Modo mayor = T-T-S-T-T-T-S
En la figura os pongo el ejemplo de DO mayor y LA♭ mayor (o SOL # mayor):
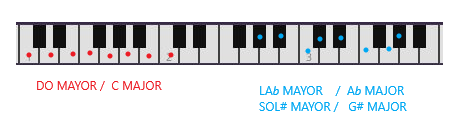
Major scales/Escala mayores
Escuchemos como suena:
- Do mayor
- La bemol mayor
- Do mayor una escala más alta que en 1.
- La bemol mayor una escala más baja que en 2.
Se observa que las notas blancas del piano se corresponden directamente con las notas de la escala de Do mayor. Además, en un piano, do mayor es la escala mayor más fácil de tocar y por eso se suelen empezar a aprender a tocar el piano con canciones en esta escala.
Se suele utilizar para expresar alegría, motivación, serenidad, etc.
PRUEBA: Interpretar en el piano las escalas de DO mayor, SOL mayor, RE mayor y Si♭ mayor.
Modo menor
De forma esquemática -> Modo menor = T-S-T-T-S-T-T
En la figura os pongo el ejemplo de LA menor y DO menor:
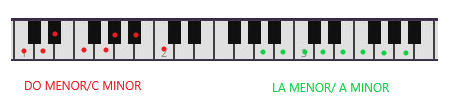
Minor scales/Escalas menores
Se observa que las notas blancas del piano se corresponden directamente con las notas de la escala de LA menor. De nuevo, la menor es la escala menor más fácil de tocar y por eso también se suele comenzar a aprender a tocar el piano con canciones en esta escala.El modo menor se utiliza para expresar tristeza, tensión, etc.
PRUEBA: Interpretar en el piano las escalas de LA menor, DO menor, RE menor, FA# menor.
Mayor vs menor
En este tutorial nos ceñiremos al uso de Do mayor y La menor únicamente. Ahora vamos a hacer un experimento sencillo:
- Componemos una canción en Do mayor y la escuchamos
- Luego desplazamos todas las notas dos teclas blancas (ojo que no estoy diciendo semitonos, ni tonos). Es decir las notas Do, Re, Fa las transformamos en La, Si, Re.
- Escuchamos ambas canciones seguidas.
Vamos a ello:
1. Canción en Do mayor:
Do-3 Re-3 Mi-3 Sol-3 — Do-3 Re-3 Mi-3 Sol-3 – (pausa) La-3 Si-3
Do-4 Re-4 Mi-4 Sol-4 — La-4 Mi-4 La-4 Re-4 – Do-4
2. Canción desplazado (a La menor)
La-2 Si-2 Do-3 Mi-3 — La-2 Si-2 Do-3 Mi-3 – (pausa) Fa-3 Sol-3
La-3 Si-3 Do-4 Mi-4 — Fa-4 Do-4 Fa-4 Si-3 – La-3
3. Lo escuchamos:
Creo que se ve claramente el efecto que produce cada tonalidad.
Cosas que se quedan en el tintero
El tintero es enorme porque me dejo practicamente todo: ritmo, tonalidad, etc. Estas cosas las iremos viendo de forma práctica en próximos articulos.
Por lo pronto, animo a los más valientes a que vayáis componiendo con Arkos Tracker 2. Cuatro pasos, que desarrollaré más en otro momento, pero que puede que os sirvan para ir probando cosas:
- Abrir Arkos Tracker 2
- Nada más abrilo siempre aparece el instrumento “First”. Usad el ratón para “pulsar” las teclas del piano y escucharlo.
- Para poder componer hay que activar el modo edición pulsando en el icono de “REC” (ver figura [me ha quedado regular, lo sé]).
- En la zona de patrones (“pattern”) podéis introducir notas en la primera columna. Las voces están indicadas con los número 1, 2 y 3 en un recuadro verde. Las notas se introducen con el teclado del ordenador:
Z=DO
S=DO#
X=RE
…
Q=DO (octava superior)
2=DO # (octava superior)
…
5. Al pulsar el icono de “PLAY” se reproducirá la canción.
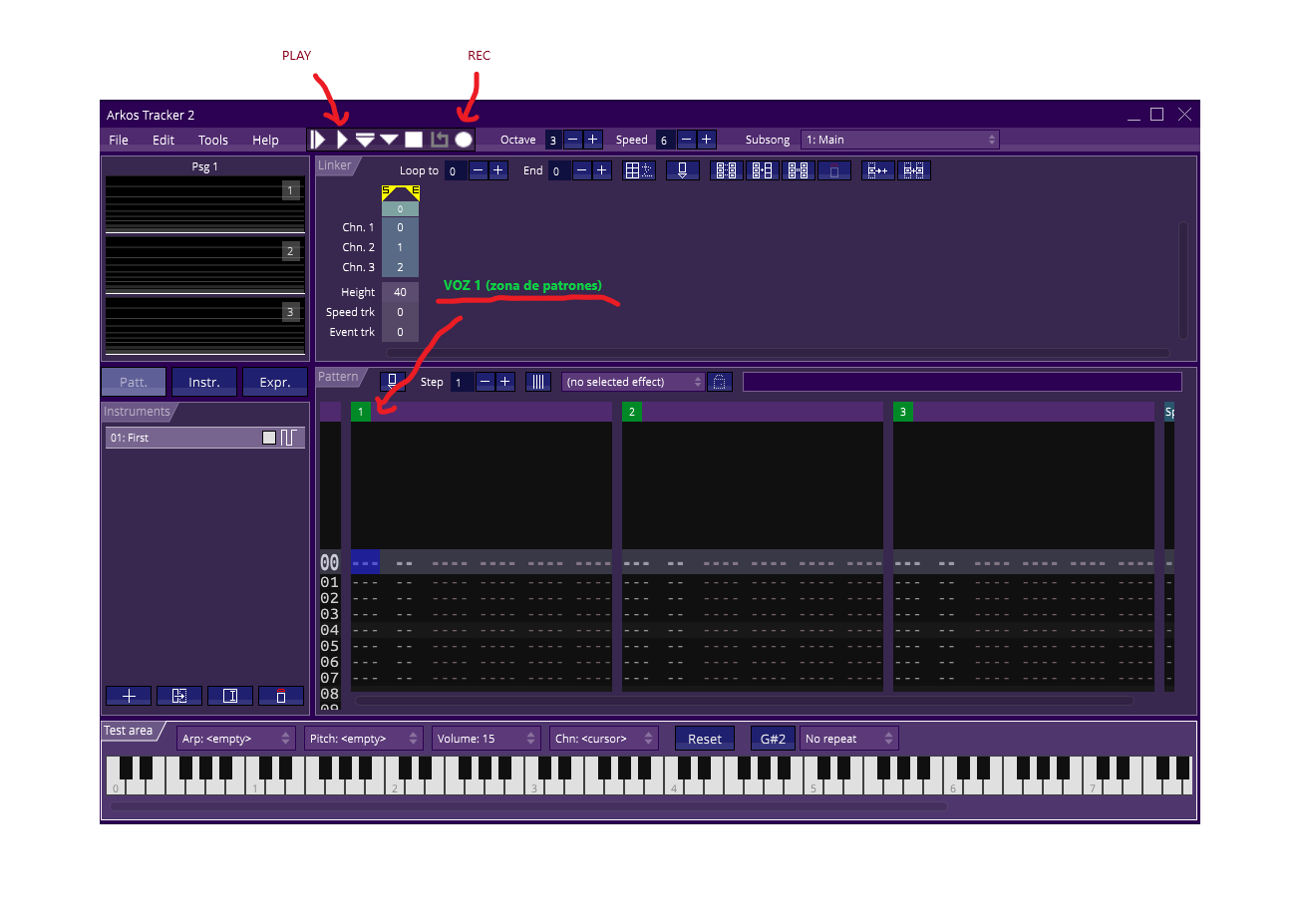
Arkos Tracker 2
Nuevo (10/11/2019): He preparado una “Introducción minimalista a Arkos Tracker” para que sea más sencillo arrancar con la herramienta y para poner en práctica los temas que hemos tratado en este artículo.
Aquí lo dejo, pronto empezaremos a aprender a usar el tracker y veremos trucos de composición para 8 bits.
¡Practicad las escalas!


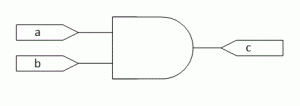
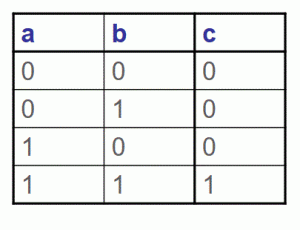 Figura. Puerta AND y su tabla de verdad
Figura. Puerta AND y su tabla de verdad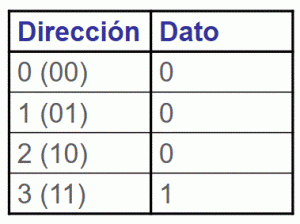 Tabla: Interpretación de la tabla de verdad como una memoria
Tabla: Interpretación de la tabla de verdad como una memoria




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}